|
第4回マーケティング/PR テクノロジー研究報告会レポート「ソーシャルメディアと日本語テキストマイニング ― 生活者の声をマーケ・PRに活かす ―」 |
#いまマーケティングができること
第4回マーケティング/PR テクノロジー研究報告会(春のリサプロ祭り・オンライン) > 研究会の詳細はこちら
テーマ:ソーシャルメディアと日本語テキストマイニング ― 生活者の声をマーケ・PRに活かす ―
1. 講演「ソーシャルメディアと日本語テキストマイニング ― 生活者の声をマーケ・PRに活かす ―」
四家 正紀 氏(アジャイルメディア・ネットワーク株式会社 ソーシャルメディアスペシャリスト部 シニアコンサルタント)
2. 日本語テキストマイニングに関するディスカッション
日 程:2022年3月19日(土)14:45-16:15
場 所:Zoomによるオンライン開催
【報告会レポート】
今回は、「ソーシャルメディアと日本語テキストマイニング ― 生活者の声をマーケ・PRに活かす ―」と題し、アジャイルメディア・ネットワーク株式会社 ソーシャルメディアスペシャリスト部 シニアコンサルタントの四家 正紀 氏から、KH Coderを活用しての日本語テキストマイニング事例を講演いただいた。

精密機器メーカーのモニター希望者を対象としたNPSロイヤルティ調査での活用例
推奨意欲11段階のNPSを推奨者(9-10)、中立者(7-8)、批判者(6以下)の3グループに分類し、各グループの自由記述文「その点数をつけた理由」をテキストマイニングして比較。
その際の特徴として、「推奨者」と「批判者」両方のポジションに近いワードがあった。
ともに、交換部品の点数(多い・少ない)への記載があり、批判者は部品の点数に誤解があった。
この分析結果をもとに誤解を解消するためのイベントや口コミの拡散施策を実施し、大成功を収めた。
テキストマイニングングのデータ元は多岐にわたる
手入力、ダウンロード、スクレイピングなど入手手段も様々
・苦情・サポート:メールや電話(コールセンター・コンタクトセンター)などのログ
・アンケート:自由記述分の回答(FA)、他の選択式質問(SA、MA)を補完
・インタビュー:デプスインタビュー、グループインタビュー
・ソーシャルメディアに書かれた投稿発言:ECサイトのレビュー投稿など
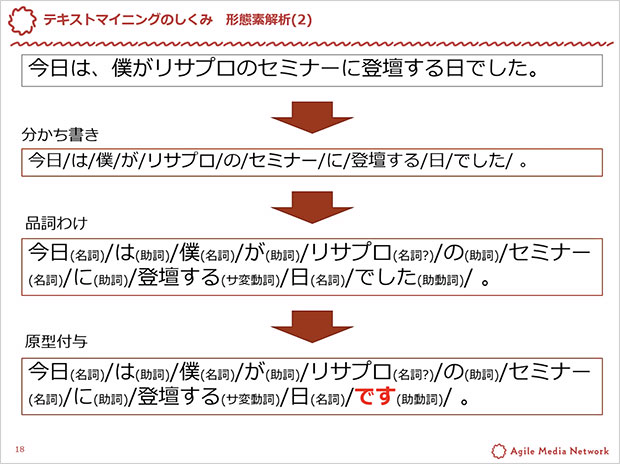
テキストマイニングングの手順
形態素解析:自然言語で書かれた文を、言語上で意味を持つ最小単位(形態素)に分割し、品詞や変化などを判別
分かち書き:文章を形態素で分ける
品詞わけ:名詞や動詞などに分類する
原型付与:単語の基本形にする(例:食べた→食べる)
マーケティングにおけるテキストマイニング 期待される成果
テキストマイニング
・多数出現するワードを中心に、全体の傾向を把握する
・出現回数は少なくても重要と思われる繋がるワードを発掘し、「気づき」につながる「ヒント」を見つける
期待される効果
・改善とその確認:クレームやアンケートから課題を抽出し改善。改善がうまく進んでいるか確認
・企画立案:プロモーション、PR企画立案、商品開発、広告やWebサイトのクリエイティブ他、様々なものに活かす
・追跡調査:抽出されたキーワードをもとに定量アンケートを設計・実施する
日本語テキストマイニングが難しい原因
・日本語は「語の抽出」が難しい(単語の終わりの判断が困難、同じ意味でも様々な表記、漢字/ひらがな/カタカナ)
・アンケートの設計が良くない(2つ以上の質問が1つになっている場合)
・ソーシャルメディアは自由すぎる(好き勝手にしゃべる、新しい言葉の出現)
自分でテキストマイニングをしてみる意味
本来、使い物になるにはある程度の時間とお金をかける必要があるが、かけても納得行かないことも多々ある。その際はとりあえず自分の手でデータをいじってみる、その過程で分かることが多い。
テキストマイニングングの手順
データ取得→下処理→抽出→解析→修正→解析(修正と解析は繰り返し)
データの取得と下処理
データの取得方法は様々な方法がある
・口コミ分析サービス:ソーシャルインサイト、つぶやきデスクなど
・フリーウェア:ついすぽ(Chromeの機能拡張)、tw2csv
・RPA:Microsoft Power Automate
・直接:サイトからのコピー&ペースト
KH Coderを活用したテキストマイニングング事例
今回の事例はTwitterのデータ2022/2/18、「カーリング」で抽出した約8万件中1万件をランダムサンプリング抽出
・下処理
・語の抽出
・多次元尺度法(MDS)で全体を把握する
・共起ネットワークで文脈を抽出してみる


まとめ
・できるところからざっくりと
・日本語テキストマイニングを「コスト」の問題で考える
第2部では、四家氏の講演を受け、研究会メンバーを交えてディスカッションを行った。ディスカッションでは以下の話題となった。
・分析のTipsについて
・データマイニングに使えるデータが少ない場合の対応
・他のフリーウェア(User Local AIテキストマイニング)について
・広報・PRでのテキストマイニングの活用の可能性
・テキストマイニング手間に対しての反応
・データの取得について
・動画や音声データの分析について
【研究会を終えて】
テキストマイニングという言葉を聞くと、専門の業者に分析を依頼するものという考えになりがちであるが、今回のKH Coderを用いた分析手法は、まず自分でやってみようと思わせてくれるものだった。ツイートデータを用いた分析をぜひ皆さんもトライしてみてはと感じた。
ディスカッションの終盤でYouTubeや音声データの分析について話題に挙がったが、AIを用いた新手法の登場が待たれるが、今回の事例のような地道な分析が、今後新手法を導入する際にも必ず活かされるであろう。
(文責:藤原 健太郎)